Map update (append)

Map update (append)

|
Re: Map update (append)
|
Administrator
|
Re: Map update (append)
|
|
Re: Map update (append)
|
Administrator
|
Re: Map update (append)
|
|
Re: Map update (append)
|
Administrator
|
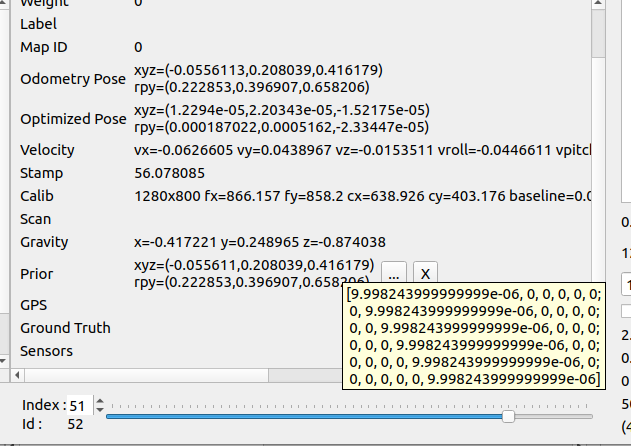
Re: Map update (append)
|
|
Re: Map update (append)
|
Administrator
|
| Free forum by Nabble | Edit this page |