In general I prefer to set "Rtabmap/TimeThr` to adjust depending on the computation power available (e.g., setting Rtabmap/TimeThr=0.7 when Rtabmap/DetectionRate=1), though "Rtabmap/MemoryThr" can give more similar results on different computers (as it is independent of the computation power). Both parameters will trigger memory management approach of RTAB-Map. When using memory management, we should use RGBD/OptimizeFromGraphEnd to true to avoid the robot to jump, this makes the map always transformed in odom frame (/map->/odom will be always identity). The parameter "Mem/RehearsalSimilarity" should also be carefully tuned, not too high or too low otherwise always old nodes from WM will be transferred to LTM first, removing the ability to find loop closures on old nodes. In general, to tune it I would do a mapping session and check "Memory -> Rehearsal sim" statistics:
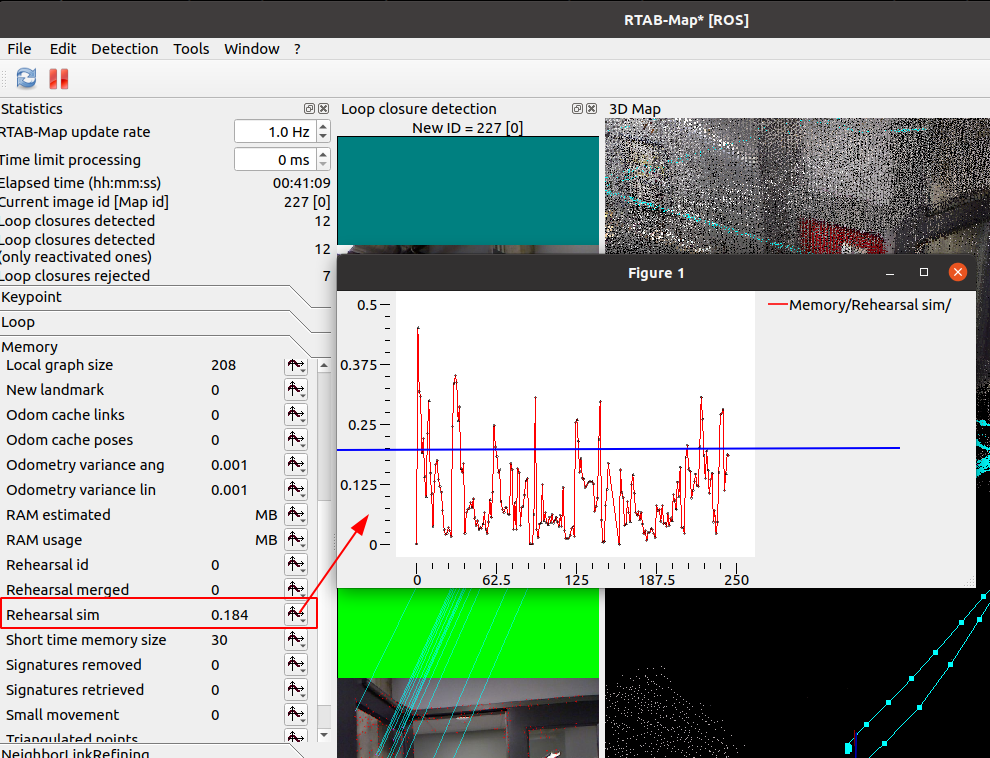
In this case, I would set the parameter to "Mem/RehearsalSimilarity=0.2" so that the weight of the nodes (over that threshold) are uniformly distributed in the environment while not adding too many of them.
For path planning to an area that is transferred in LTM, you would have to call "/rtabmap/set_goal" service to a known node id or label:
rosservice call /rtabmap/set_goal "node_id: 0
node_label: ''
frame_id: ''"
To make it easier, I'll suggest to label important locations while mapping (e..g, "aisle_1_B", "aisle_1_C", "aisle_2_A"...), so that when the robot has to go to "aisle_1_B", we call:
rosservice call /rtabmap/set_goal "node_id: 0, node_label: 'aisle_1_B', frame_id: ''"
On success, rtabmap will make sure to transfer back nodes from LTM to WM to be able to localize while following the path (successive goals are published on /rtabmap/goal_out). To more in-depth details, see this paper on how it can be integrated with move_base: "
Long-Term Online Multi-Session Graph-Based SPLAM with Memory Management"
General thoughts: Note that if you are planning to map the whole warehouse, then use the map in localization mode, and if you don't care to actually see in real-time the loop closure detected while mapping, you could disable loop closure detection (Kp/MaxFeatures=-1) and just make rtabmap accumulate the nodes in the database. Offline, use `rtabmap-reprocess` while re-enabling loop closure detection (adding option "--Kp/MaxFeatures 500") to remap without memory management. In localization mode, rtabmap should be able handle online very large maps without the need of memory management. The memory management approach is mostly useful when we want to do continuous SLAM.
cheers,
Mathieu

