More loops isn't always better


|
Hi Mathieu,
I have come to notice that very often, loop closures can be detrimental if there are too many of them. To the point that I have not stopped using the detectMoreLoops tool, going for manual frame by frame loops using the databaseViewer instead. For huge projects though (> 100,000 nodes), it is too much work, hence I have no real solution right now. For all my big projects I've been using an iPhone, so that registration is done with PnP using the ARKit depth map. Knowing how little precision those depth maps have, it makes sense that although a global loop can be very helpful to solve a large drift, their covariance is pretty high and too many of them will overtake the effect of odometry. I have been trying to understand what is happening and how to possibly find a solution to the issue. To explain a bit my situation, here is a list of cases that happen in my scans, which require different density of loop closures : - when scanning a "straight" gallery, no extra loop can beat ARKit odometry so that usually, the loops between node n and node n+1 detected by detectMoreLoopClosures are just detrimental. I have made many tests and I have come to the conclusion that raw odometry is in that case better than a reprocessed database, whatever parameters I chose - when scanning a very large area which requires to walk all around the place several times to cover it fully, needed many loops, the output of rtabmap-reprocess is usually very relevant and is able to detect most important global loops. If some are missing, one iteration of detectMoreLoops with strict parameters helps. If more are still missing, more iterations are again helpful in the way that "double walls" tend to disappear, however the density of global loops gets larger and larger until it overpowers odometry and although local geometry is fine, the global graph is deformed and impossible to georeference - when multi-session-scanning a place where some galleries appear twice in the final merged database, it can be that this results in a double-gallery if rtabmap-reprocess hasn't figured out that they are the same. Adding one manual loop with rtabmap-databaseViewer works very well in that case. On the other hand, rtabmap-detectMoreLoopClosures will typically add loops "path1[i] -> path2[i] for many i's" if that makes sense. Several iterations will add loops "path1[i] -> path2[i+1]" and so on, until the loops overpower the odometry of the two paths. - when scanning a huge area which is a mix of straight galeries, larger places, intersections, multi-session scan with some overlapping, possibly challenging loop closures, all above issues appear. A simple reprocessing isn't usually enough to close the necessary loops, and repeted iterations of detectMoreLoopClosures will eventually deform the final graph. Several tests show huge angular drifts due to one iteration of detectMoreLoops, leading to hundreds of meters of error on the final graph although the odometry graph was a very good initial guess. Now here are my attempts at understanding what is going on : - hundreds of thousands of global loops will overtake the weighted cost in graph optimisation. Hence, a way to deal with the situation could be to increase global loop covariance the more you add loops. I have tried to put 9999 covariance on global loops in my example mentionned above where the final drift about a hundred meters, and the result was almost no improvement. Very far from the intial odometry graph. - another concern I have is about the computation of the links' covariance. I was initially expecting a covariance on rotation R and translation t derived from PnP reprojection Jacobians. In practice, the covariance associated with PnP links appears to be a diagonal, heuristic estimate based on median residual errors, with translation and rotation treated independently. As a result, correlations between rotation and translation are ignored, and the conditioning of the PnP problem itself is not reflected in the information matrix. I'm wondering why Vis/PnPSplitLinearCovComponents is set to False by default. More generally, I would be interested in your thoughts on whether this covariance approach is appropriate for very large graphs with dense loop closures, or if a more probabilistic PnP uncertainty model could help mitigate the undesired effects. Finally here are some ideas on how to adress the issue. They shouldn't be taken as "suggestions", rather, attempts at spotting the possible sources of errors, and inputs for discussion. - in some way, part of the problem isn't really about individual global loop covariance but more about local accumulated covariance. If one wishes that odometry links overpower global loop closures for local geometry, then the local contribution of a node to the graph optimisation should be a sum of the odometry contribution and the global loops contribution, normalized by the number of global loops in a local neighborhood ? - if many iterations of detectMoreLoopClosures eventually does find all necessary loops, but one ends up with too many of them, a "filter" could be applied to get rid of the redundant ones. Typically, two nodes which are close to each other in the odometry graph shouldn't be globally looped. More generally, two nodes which are already close in the full graph shouldn't be concerned with any extra loops. A way of filtering could be to run over all nodes, intersect the graph with a spatial neighborhood of fixed radius around that node and greedily remove global loops according to covariance as long as the intersected graph doesn't get disconnected. Another less brutal approach would be to set parameters like "LoopClosureMinLength" which allows the user to specify the minimum distance between two nodes in the graph before a new loop can be added. This sounds to me like a simple option which could adress most of the issues. I'm sorry for this very long post, I hope it is worth your time reading it. I thank you for any discussion on this matter :) Pierre |
|
Administrator
|
Hi Pierre, here some of my thoughts
If loop closures make it worst, it could be because the loop closures' covariance is too confident (too small) and/or odometry covariance is not enough confident (too large). For example, with rtabmap-databaseViewer, you can change the covariance of all neighbor links to something very small (Edit->Update all neighbor covariances...), if close to 0, the loop closures won't bend the odometry constraints at all. At the inverse, you can experiment with larger covariance for loop closure constraints (Edit->Update all loop closure covariances...). There could be improvements to make rtabmap-detectMoreLoopClosures adding more intelligently loop closures, assuming that odometry constraints are always better. For example, we could define a new parameter that will set a minimum distance in terms of nodes between two nodes checked for loop closure. It is different than the current parameter setting the minimum radius (-rx), which doesn't allow two close nodes (in optimized graph) taken a long time apart to produce a loop closure. In your case, maybe the odometry covariance is too large, see previous comment try with smaller one. Don't put 9999 covariance, but try 9998. There are many places in the code that will detect >=9999 as invalid or will adjust which kind of constraints are added in the optimizer (for example, we can treat a prior with 9999 rotational covariance as a EdgeXYZ constraint instead o EdgeXYZRPY, thus ignoring completely the rotation in the optimization). Setting covariance that high could generate issues in the optimizer where constraints are underestimated and won't converge at all. However, in theory, in single session maps, setting very covariance on loop closure links should make the optimizer converging only on the original odometry poses. For multi-session maps, at least one loop closure link between two different sessions should have appropriate covariance, otherwise the optimizer would likely diverge. The covariance model could indeed be improved. We made one based on the 3D correspondences between the features as opencv's solvePnPRansac doesn't provide any feedback (or internal computed errors on the transform) from its optimization. Vis/PnPSplitLinearCovComponents is false because it was probably an experimental test with which I didn't see significant difference with the previous approach. Note that my experience with covariance tuning is that there will be always an event or external factors in the real-world that will make the computed covariance (even if mathematically correct) fails because it underestimated or overestimated the real error (by lack of necessary features to actually converge to real global minimum). On the iOS app, the odometry covariance is currently eye-balled and fixed, because ArKit doesn't provide any error in their pose estimation. It could be lowered, but ArKit drift is not constant, so we cannot make it too small to avoid over confidence that will reject any loop closure detection down the road. Looks like I should have read your whole post before starting answering above. I think "LoopClosureMinLength" is exactly what I was think about earlier. Thanks for the feedback about rtabmap-detectMoreLoopClosures, I created a ticket about adding a parameter like "LoopClosureMinLength". |
|
|
Hi Mathieu,
I realised only very recently that you brought a solution to the problem very quicky, thank you so much ! Some issues that I have with the rtabmap-reduceGraph tool: - I often have the following error message: Parameters: radius = 0.100000 m keep_latest = false keep_linked = false pre_cleanup = false Database: merged.db Initialization... Fatal Python error: take_gil: PyMUTEX_LOCK(gil->mutex) failed Python runtime state: unknown Aborted (core dumped)whether pre_cleanup is true or false. Sometimes I have this issue, and trying the same command a second later starts it successfully... - when the command does start, I usually have unreasonably long "Initialization" times. For instance, I waited for more than 24h on a 17gb database before giving up - I'm wondering if it could be possible to just ask for this pre_cleanup, and make it into a "cleanup", without reducing the graph. I'd like to get rid of parasite user loop closures without collapsing nodes. Another thing I'm wondering is why considering user loops instead of global + user loops ? The issue of too many global loops being added to the graph does exist when one scans the same place twice : many global loops are detected and overpower/damage the odometry. This isn't really specific to user loops or the detectMoreLoops tool. I thank you very much for your responsiveness and great help, Pierre |
|
Administrator
|
Hi Pierre,
The python error could be caused by rtabmap built with Python support and the tool doesn't initialize python correctly. Is your database using PyDetector or PyMatcher related parameters? I added this commit to properly initialize the PythonInterpretor. The initialization time is dependent on the database size, you may launch with `--udebug` argument to show where it is stuck. Unfortunately, this current version of ReduceGraph is using the Memory object to manage the graph and the vocabulary, thus the whole map has to be loaded in RAM. After initialization, the graph reduction process should be pretty quick though. The "pre_cleanup" step has been added for convenience (and backward compatibility) to cleanup maps on which we did "add more loop closures" with previous versions. The "add more loop closures" process adds only "user" loop closure type, that is why that option only checks for user links. The "pre_cleanup" step is very specific to remove any user loop closures linking nodes that are very close to each other in time (under Mem/STMSize set in the database). The new version of ""add more loop closures" tools doesn't add anymore loop closures between nodes close in time, so "pre_cleanup" is unnecessary with databases created and updated with latest rtabmap version. I am not sure exactly what behavior you would want for a "cleanup" standalone tool. For actual loop closures between two different path taken long time apart, the odometry links should not be too much affected (relative to each other close in time), unless their covariance is too large. cheers, Mathieu |
|
|
Hi Mathieu,
Thanks for the commit it did solve the error ! I am using pymatcher indeed. Ok I understand that everything is loaded in the ram, but then this means I cannot use the tool sadly (my databases are often >=200gb). Also I understand that detectMoreLoops is only adding user loops, my point was that already during reprocessing, too many global loops are added in the sense that if gamma(t) and gamma'(t) are two similar trajectories (scanning the same corridor twice) then global loops between gamma(t) and gamma'(t) will often be added for all t. Although one could expect that a global loop isn't added during reprocessing if the two nodes are already less than STMSize nodes appart. Here is an example of a database that has been reprocessed, without detecting more loops: 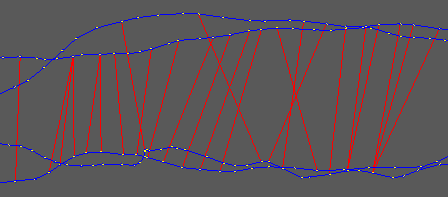 Obviously in this case the global loops are not going to overpower the odometry links but we can see some loops gamma(t) <-> gamma'(t) as well as gamma(t+1) <-> gamma'(t+1). Basically if I were to chose the way it is implemented, I would go for something inside the databaseViewer gui (so that the graph isn't loaded in RAM), like Edit/Reduce links density, which would open the exact same popup as Edit/Refine links, with an additional parameter 'Maximum distance'. But I undestand that the use of this tool would be quite niche (repairing databases on which the old detectMoreLoops has be run, or the new one if STMSize was too small). On the other hand, it would make the tool useable for large databases. But maybe the most appropriate solution for this is to make a small dedicated Python script. I hope I made myself clearer :) Thanks a lot. Pierre |
|
Administrator
|
Hi Pierre,
For the memory usage issue, if you can show the debug log it would be useful (or a rtabmap-info to show how big the vocabulary is). I already changed some parameters to initialize the memory with the minimal data (only the graph and the visual words vocabulary, the actual signatures should be mostly empty). Unfortunately, the visual words vocabulary is the one that would take significantly more time to load, even if it is not necessary for the graph reduction itself. I'll be working on graph reduction in the next weeks, so I may come with a workaround at some point. For the graph's cleanup you are referring, that could be possible to do. With sqlite3, we can already remove all loop closure links in one command: sqlite3 rtabmap.db "Delete from Link where type != 0"Assuming the current optimized map in the database contains all nodes, from python's sqlite3 it could be possible to get the graph from https://github.com/introlab/rtabmap/blob/aa6d20775f71dcfa597046c5f28ba38c66546d9a/corelib/src/resources/DatabaseSchema.sql.in#L124-L125, with the poses of each node, you could load all links from sqlite3 and check all of them in a loop to keep only one link in some density. However, if there are multiple paths overlapping together, it may be not trivial to know which links to remove, because it looks more like a density filtering between two paths, not a density in space between all superposed paths. I could still see another usage for that kind of tool to reduce graph optimization time. Looking at your screenshot, maybe just reducing the error covariance of the odometry links or increasing the error covariance of the loop closure links could already fix the issue without removing any links. cheers, Mathieu |
|
|
This post was updated on .
Hi Mathieu,
Some feedback about the new parameter. It is really life-changing, but the way you implemented it isn't fully solving the issues that I usually have with large multi-session databases where the trajectory can come back to the same place many times. However I understand the choices you made for your implementation and that they might be better for the standard usage of the app. Here are the few things that I had to change to make detectMoreLoops work perfectly in my scenario: - you filtered links to keep only neighbor links, so that graph distance is calculated in the odom graph. In my case it is needed to keep all links, otherwise many loops can still be detected at the same place. Keeping only neighbor links solves the loop accumulation locally in time, but not globally, in particular not inter sessions. - you trimmed all clusters once and for all before starting to detect, but if we want all links, then we have to trim little by little inside the loop, calculating graph distance with an up-to-date list of links, that we update everytime a loop is added. I implemented those minimal modifications and got a very good result with the largest database I have, which is a sort of underground quarry maze with complex gallery geometries, covering sparsly an area of about 60,000m^2. Those modifications allowed for an odometry driven graph, with a small collection of relevant but non redundant global loops, which gave me the best result I ever got by now. It’s nothing crazy but I don’t think it’s possible to get such a result with the current version of rtabmap. But again, I understand that this behavior of detectMoreLoops might not be the one you want for the general user, so, if you are interested here is the link to my fork, and I'll let you decide whether you would consider updating the main branch with those changes or not : Branch: detectMoreLoops_newstrat Note that I also did the following additional modifications: - the original strat makes it impossible for a node to participate to several loops. It makes the detection way faster but could potentially miss relevant loops. On the other hand, minimumGraphDistance can also be considered as a way of making the detection faster. If minimumGraphDistance > 1, I chose not to keep the original strategy, and to keep it otherwise - I added a small logging of attempted registrations, which is essential for my huge projects because it makes it possible to initialise checkedLoopClosures with that of the previous runs. However the current implementation only makes sense if one uses RGBD/OptimiseMaxError 0 which I do. I don't think that the current state of this feature is mature enough for a pull request, it is probably irrelevant actually for any classical use of the GUI. Improvements would be to log all the infos about each loop: #PnP inliers, #Matches, PnP covariance, as well as the reason for the potential loop rejection (OptimiseMaxError for example). Then this log file could be loaded and filtered according to the current core parameters. Loops which were rejecting purely because of OptimizeMaxError can then be given another chance, etc. Some metadata are easy to log, like OptimizeMaxError which would already make the feature more generalizable. Others will require more work because it eventually boils down to modifying util3D and many other things recursively. Anyways thanks a lot for your help Mathieu ! Bonus: here is part of what my assembled scan looks like, about 50 sessions merged. As close to ground truth as it could ever get with the new strategy. 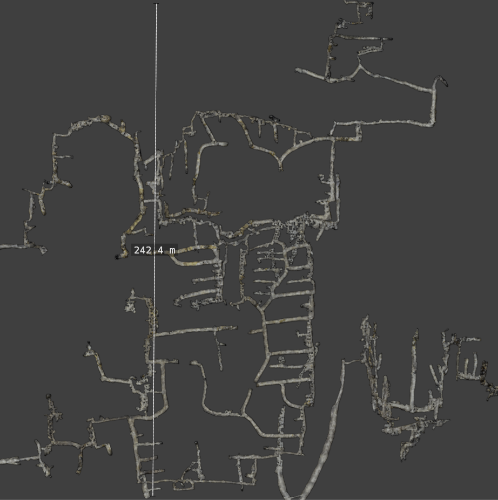
|
|
Administrator
|
Thanks for sharing your experience and the changes you did. I'll keep this thread on top of my list to look more in depth in the next days. I am open to add more options to produce the same effect you want. Otherwise, very cool map!
Mathieu |
|
|
Hi Mathieu,
I've been thinking about the possible ways of introducing the "loop detection log" inside RTABMap, and there is one solution which I believe could integrate naturally to the existing workflow. On top of neighbor, proximity, global and user links, there could be a "rejected" category. Moreover, if the user choses the appropriate set of options (i.e. "keep rejected links" and "store link metadata"), some information about the link could be added as attributes to the Link class: detector and matcher used, number of PnP inliers, PnP reprojection error, etc., as well as the reason why the loop was rejected. Then, when detecting more loops, the user could chose "ignore already rejected links". If not ticked, the previously rejected link would be reconsidered as a potential loop if any of the conditions is verified: - detector or matcher has changed - user relaxed the parameter which caused the rejection - the reason of the rejection was a geometry-dependant check, typically "error > OptimiseMaxError" This is just a simple suggestion, but I wouldn't consider asking for a feature request at this point because my current small changes are enough for me right now. Thanks for everything, Best, Pierre |
|
Administrator
|
Well, in general most of the rejected links would be real bad links. If most are actually good, then there is an issue upstream that is rejecting too many good loop closures (e.g., bad odom covariance, too strict parameters). If most are bad, that would still need to be carefully analyzed from the user to know if there were in fact good. It takes only one bad loop closure to catastrophically break the map. Note that we added a new mechanism recently to be able to reject past bad loop closures that were wrongly accepted (repairing the graph), in order to avoid rejecting all new loop closures because of one bad loop closure accepted in the past.
We already have (kinda) that information through the Statistics "Loop/" group. When a loop closure is rejected, based on the filled info, we can track down the reason why that loop closure was rejected (e..g, failed graph optimization ratio, failed min inliers, failed correspondence ratio for ICP) while having info about the number of matches/inliers for that loop closure. The idea to make "detect-more-loop-closures" tool read these Statistics to avoid re-trying to add the same loop closures that we know are bad, that could save some time, though probably marginal. Regards, Mathieu |
|
|
Oh I didn't know all this information was already in the database, thanks. I'm fine with keeping this in my own personal fork, this probably doesn't deserve to be added to the main project.
I agree that for most use cases the time save is probably marginal, although in my case one iteration of detectMoreLoopClosures can easily take 4 full days according to how large of a radius I chose. Starting a second iteration skipping the already "tested and rejected" loops reduces time by one order of magnitude. But this is very specific to large databases I guess. The only thing that - I think - could deserve some update is the distance calculation strategy: distances are currently computed in the odom graph and link candidates are pruned in preprocessing; in my small update I chose the main graph instead and calculated distances little by little to take new loops into account. Thanks for the discussion Mathieu, I consider this topic solved on my part :) Pierre |
|
Administrator
|
Hi Pierre,
In the statistics, you may be able to know when "Loop/RejectedHypothesis/" is one (true) that a loop closure has been rejected between the statistics's ID (which corresponds to the same node ID) and "Loop/Highest_hypothesis_id/". The distances should be computed in optimized graph. Then the clusters (potential loop closures) are recomputed with the latest optimized graph (including new loop closures) after each iteration. Regards, Mathieu |
|
|
Hi Mathieu,
I was mentionning the detectMoreLoopClosures inside the databaseViewer class from the begining, sorry for the misunderstanding. I believe that in this version, distances are calculated in the graph with a fixed set of links, which are chosen to be neighbor links only. Also, this set of links is not updated between iterations. My solution was to take all links instead, and update the set of links with newly added links little by little (not just after the end of an iteration). This allows to always calculate distances in the up-to-date graph, otherwise it can still happen that two loops are added within less than minimumGraphDistance. But maybe I was completely miunderstanding something ? Best Pierre |
«
Return to Official RTAB-Map Forum
|
1 view|%1 views
| Free forum by Nabble | Edit this page |