Hi Mathieu,
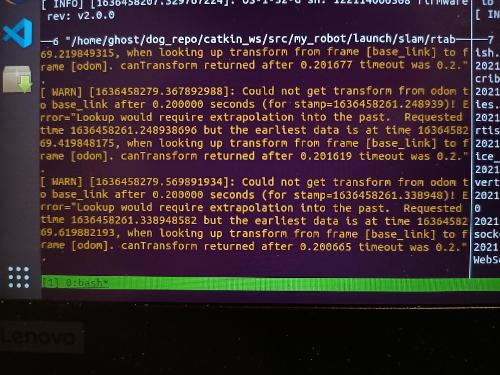
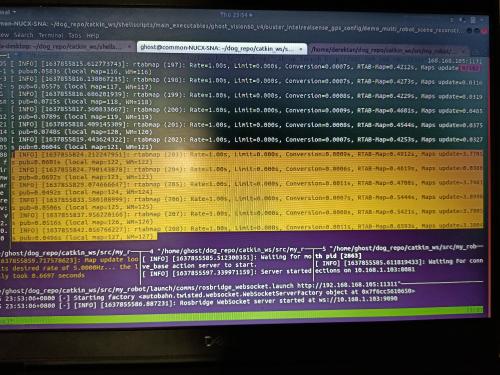
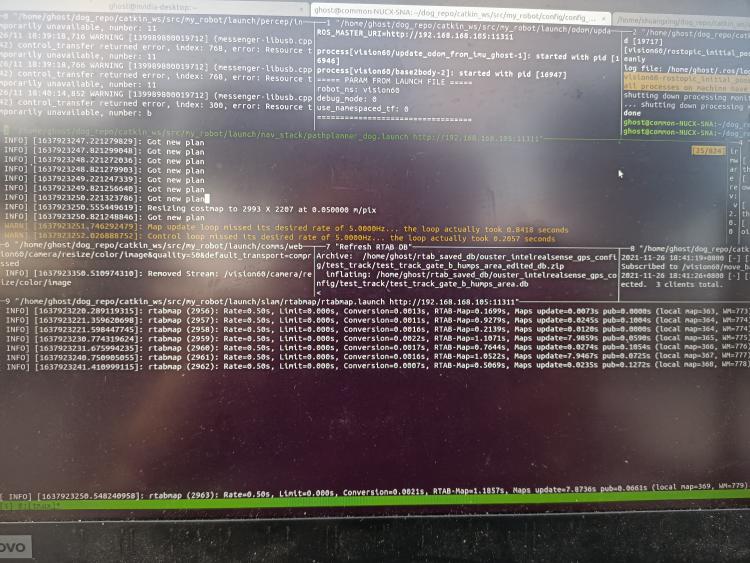
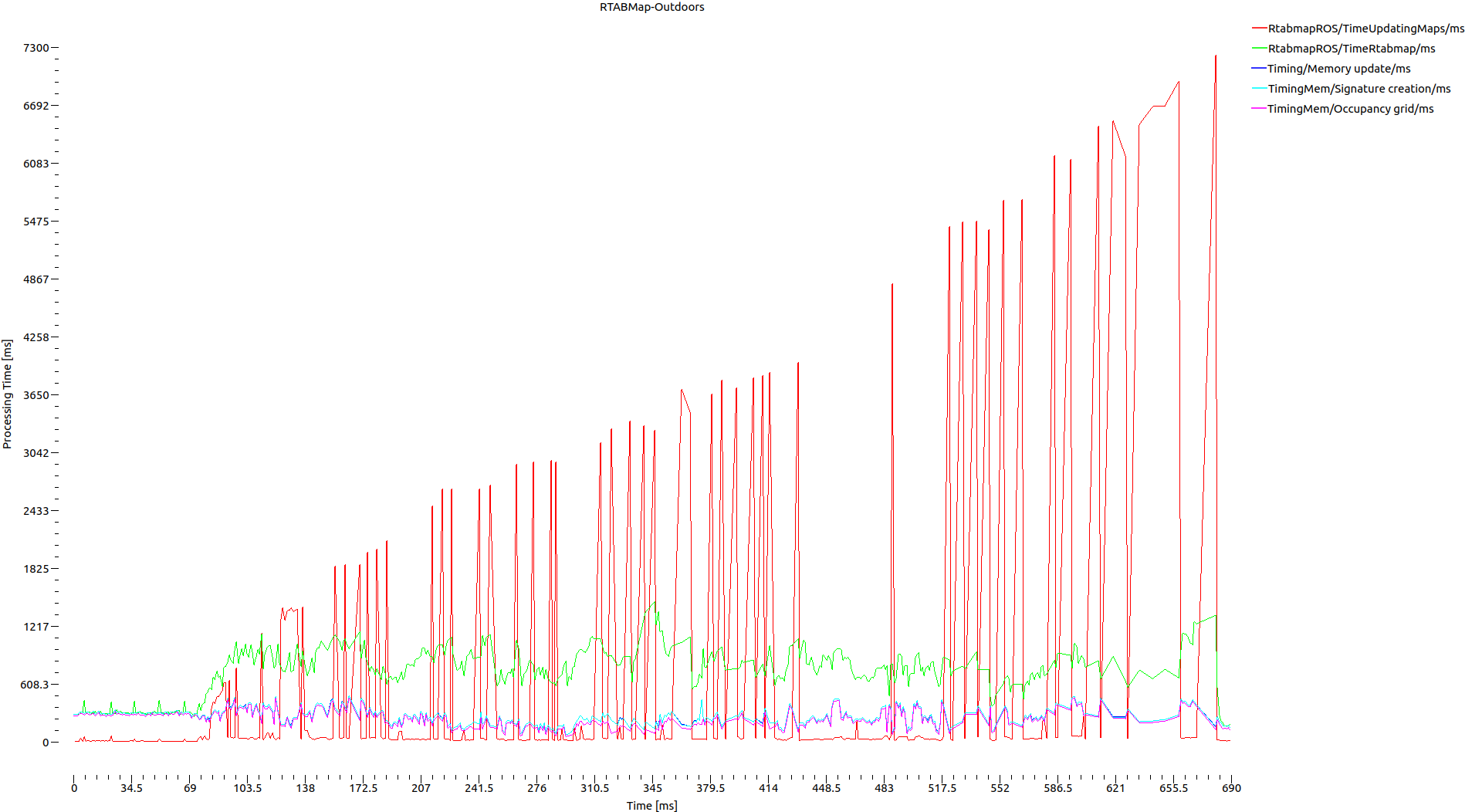
That's a great point you have raised there; updating the map via 56M operations does seem to point to the long mapping update duration we have observed. Your recommended method of limited the size of the assembled occupancy grid seems like the most viable option for long-term SPLAM operations. I would like to clarify the difference between some of the memory management parameters. Please do correct me if I'm wrong.
What is the difference between GridGlobal/MaxNodes and Rtabmap/MemoryThr?
From my understanding,
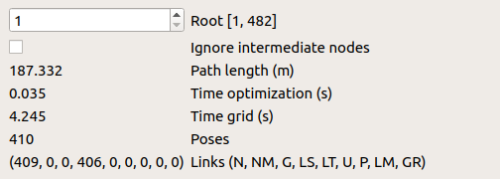
Rtabmap/MemoryThr moves some of the less important WM nodes (older and less weight) to LTM, in order to maintain a fix number of WM nodes for consistence mapping performance. These LTM nodes will no longer be considered for graph optimizations unless a loop closure is found (weight of LTM in the near vicinity will increase and be retrieved back to WM). Only nodes in WM will be used for the assembly of occupancy grid.
On the other hand,
GridGlobal/MaxNodes tells Rtabmap only to use a fix number of nodes close to the robot for the assembling of occupancy grid. This is basically the same as setting
Rtabmap/MemoryThr, from the perspective of occupancy grid assembly, However, this parameter does not force rtabmap to move nodes to LTM, causing the number of WM nodes to grow unboundedly. Even if we were to maintain low map update durations, we may eventually come to a point where loop closure detection takes too long due to the large WM size.
If my understanding is correct, setting Rtabmap/MemoryThr rather than GridGlobal/MaxNodes seems to be a more robust approach? I am currently rather hesitant to set
Rtabmap/MemoryThr or
Rtabmap/TimeThr. I have noticed that the global costmap sometimes becomes distorted whenever some nodes are moved from WM to LTM, similar to
what someone else has pointed out. In fact, I suspect that
one of my older problem is associated to this. I am not sure if you have any experience with the new global costmap generated by move_base not fitting the new 2d map generated by Rtabmap?
Merry Christmas to you,
Derek