Mysterious error regarding tf timeout

Mysterious error regarding tf timeout

|
This post was updated on .
Hi Mathieu,
Hope you are doing well. I am currently facing a weird error regarding tf timeout, as shown in the picture below. I never had any problems with this before, but started facing this issue when I'm running RTABMap in localization mode. I managed to fix the issue when I ran RTABMap localization mode using another .db file. Unfortunately, I have no clue why changing my .db file is related to this issue. Furthermore, in mapping mode, things were going fine for the first minute or so before I encountered this issue again. Another observation I had was that the timestamp divergence between incoming tf message and the current system time increases with time, up to 10s of seconds. More context here. Currently from an external miniPC, I am retrieving odom message and odom-base_link tf from my robot's internal PC. I made sure to sync both computers perfectly using Chrony, and it had been working well for the past few months. A few months back, I was configuring RTABMap to work with robots individually (not namespaced), and all was good. In recent weeks as I was namespacing my robots' topics and nodes to perform multi robot mapping (as discussed in this post), I began having this problem. I'm sure that the tf tree is connected by checking rosrun tf view_frames. I highly doubt I made any mistakes in the namespacing process. What stumped me most was the fact that changing the .db file averted the problem altogether. Do you have any insights to this issue? I'm tempted to set 'wait_for_transform' to a high value, and maybe setting 'sensor_odom_sync' to true, though I don't think that resolves the crux of the issue. Any insights? Regards, Derek Tan 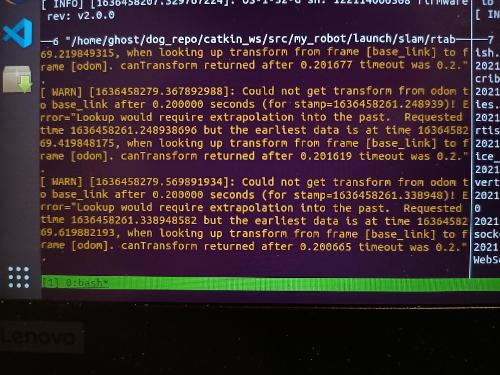
|
|
Administrator
|
Hi,
This warning will appear when rtabmap gets TF odom->base_link with the stamp from the odometry topic received, and TF has not been yet updated at that time, or it is too old (which seems in the case here). For example, if TF on external pc is currently updating at time 30 sec, but it received an odometry topic with stamp at 20 sec, which is 10 sec in the past, we get this error. I think the default TF buffer size is 5 seconds, so old TFs have been already flushed before the topic is processed. I don't think it is a database issue, but more a time synchronization issue. You can try to echo your odometry topic on remote pc and check at the same time the logs and see if there is a large difference. cheers, Mathieu |
Re: Mysterious error regarding tf timeout
|
|
This post was updated on .
Hi Mathieu,
Thanks for your insights. Just to clarify, do you mean that the timestamp of the odom->base_link tf must be exactly synchronized with the odometry message itself? I followed this tutorial to publish both tf and odom topic message at the exact same rate from the internal computer inside the robot, which is then subscribed by Rtabmap node on the external computer. http://wiki.ros.org/navigation/Tutorials/RobotSetup/Odom On a sidenote, I made sure that both internal and external computers are synced perfectly using Chrony. Very interestingly, I isolated the issue to the pointcloud input into rtabmap. If I were to significantly downsample my pointcloud (Ouster OS1-32) using passthrough and voxel filters, I won't have this error. I only face this error when I input pointcloud with minimal filters (many points). I find this a very weird error indeed. I definitely did not face this problem when using the Velodyne VLP16. Thanks, Derek |
|
Administrator
|
Hi,
Are you using PTP time sync with ouster? By default ouster point clouds are stamped from 0 sec instead of time of computer, this could create a problem if odometry is stamped with this time, when your computer uses other TF published with time of your computer. Yes odom TF and odometry topics should be stamped with same time. cheers, Mathieu |
Re: Mysterious error regarding tf timeout
|
|
Hi
Yup, just checked to ensure that the Ouster lidar is PTP time synced. I played around with some rtabmap parameters and came to realise that I've set the queue_size to 100, even though my camera frequency (30Hz), Lidar frequency (10Hz), Odom frequency (15Hz) are all rather low. Setting queue size to around 10 resolves that issue. Once this problem was resolved, I quickly noticed another issue. In SLAM mode, after perhaps 200s of robot moving around at 0.5m/s, mapping frequency slows down significantly (from ~0.03s to 4s). This is despite rtabmap frequency being low (around 0.5s). From some of the forum post, I saw that this might be a timesync issue. It's weird because this error blows out of proportion only when the robot has moved for 200s. Being stationary is fine, peessumably because no mapping is done when stationary. Parameters like odom_sensor_sync freezes rtabmap. I wonder if you have any insights? Thanks!  |
|
Administrator
|
Hi,
I don't see well the screenshot (too low resolution), but if mapping is taking 4 sec, there is a problem. What is the computer used? Also depending on the configuration, you may have to downsample the ouster point cloud. There is probably some tuning to do to use less power. You can take a look at the velodyne or ouster example (you can skip icp_odometry part if you don't use it): https://github.com/introlab/rtabmap_ros/blob/master/launch/tests/test_velodyne.launch https://github.com/introlab/rtabmap_ros/blob/master/launch/tests/test_ouster_gen2.launch cheers, Mathieu |
Re: Mysterious error regarding tf timeout
|
|
This post was updated on .
Hi Mathieu,
The links you have provided were really helpful. I followed some of your recommended parameters that works well with ouster lidar, namely reducing Grid/RangeMax and Grid/CellSize. Update map timing improved in general. I believe we are getting close to the heart of the issue. However I still noticed that there are times when rtabmap gets stuck on specific iterations. As you see from the image below, map update can spike to 7s. I noticed this happens whenever the global costmap from the navigation stack automatically resizes, which is an important feature for autonomous exploration (See pane above rtabmap's pane where cursor is at). I believe the global costmap size is linked to rtabmap via the grid_size rtabmap parameter. How is rtabmap internally linked to the ROS navigation stack's global costmap? I wonder if there are ways for Rtabmap to be independent of global costmap size? Perhaps more background on my use case. I am currently using an Intel NUC as an external PC connected to my robot. It runs all nodes, from perception, to rtabmap, to ROS navigation stack. I'm currently using it for autonomous navigation, as described in your guide here. I am using the ouster lidar to build the map, a Realsense camera to perform global loop closures, and odometry coming from the robot itself. Thanks. 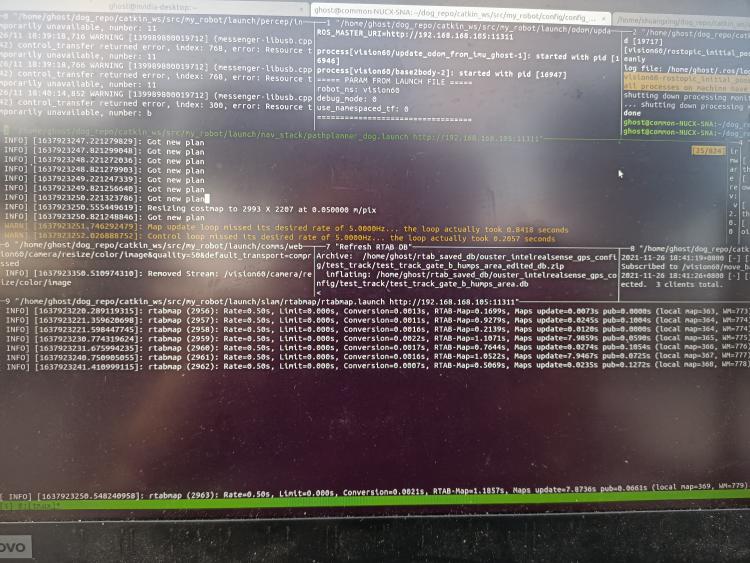
|
Re: Mysterious error regarding tf timeout
|
|
Hmm, I seemed to stop the costmap resizing issue by setting the grid_size to a large number (150). The intermittent 4-7s map update issue still persists. I will continue to play around with the parameters.
|
|
Administrator
|
Hi,
To know exactly what is required 7 sec to update, you can look at the Statistics/Timing inside the resulting database (you can browse those statistics with rtabmap-databaseViewer -> Statistics panel). The grid_size parameter is used to initialize the size of the 2d occupancy grid. If the robot goes over the bound, the grid is automatically extended as usual. The newly extended map is published to move_base, which then updates its global costmap size (there is no feedback from global costmap to rtabmap). I suspect that there is a global update (a loop closure has been detected) of the grid map internally to rtabmap, which requires rtabmap to rebuild the global map. I don't know the Grid/ parameters you are using, but if you use Grid/3D and local grids are large, this can take a while. See Table 10 of this paper for some examples of different Grid parameters. cheers, Mathieu |
Re: Mysterious error regarding tf timeout
|
|
This post was updated on .
Hi Mathieu,
I apologise for the late reply. Here are some key statistics from the database viewer: There are no global loop closure detected 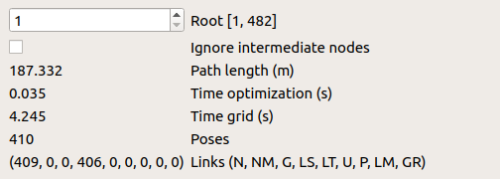 I graphed out some of the components that took the longest duration to complete: 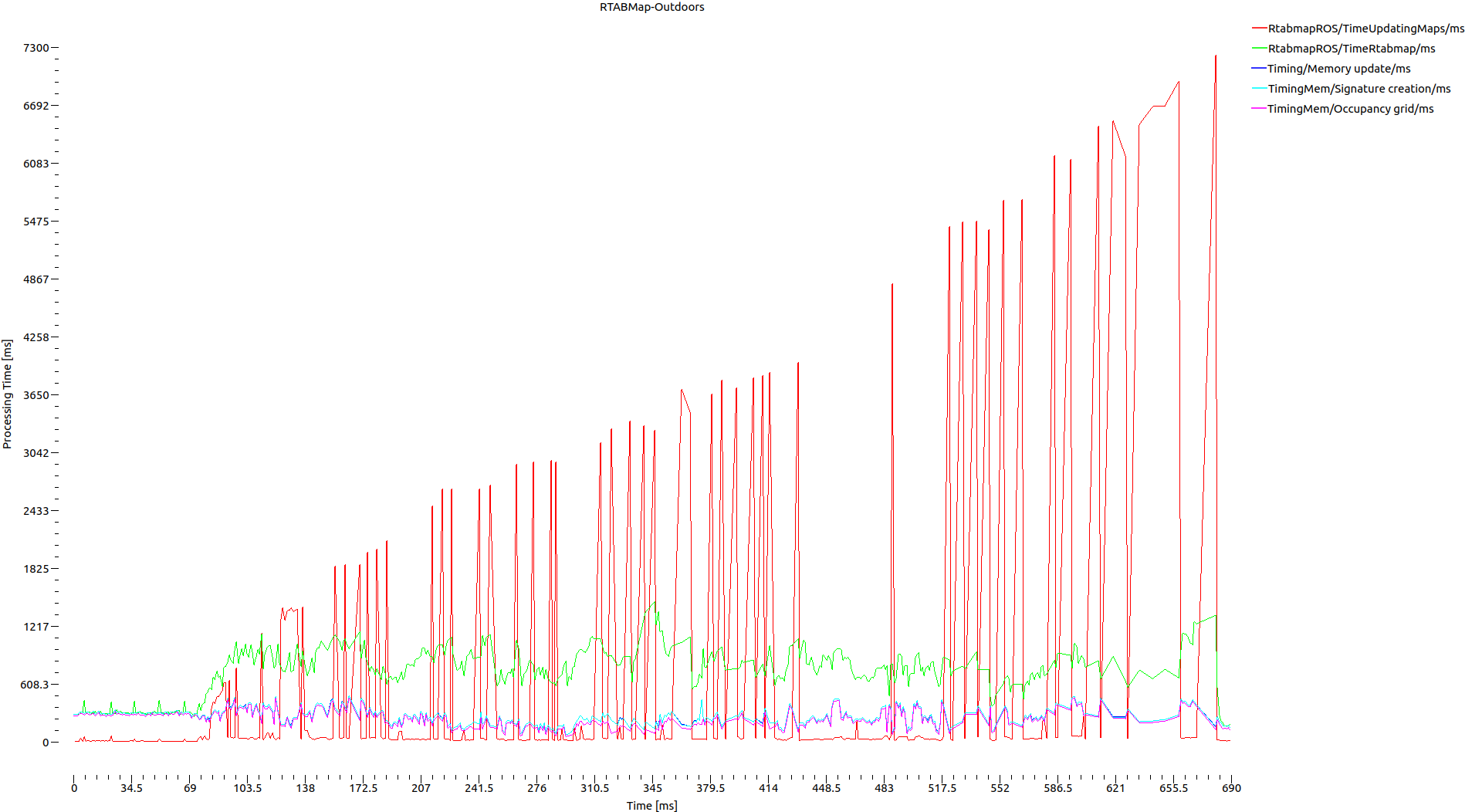 I think it's intuitive to observe the upward trend in the computation time due to increasing number of working memory nodes, given that Rtabmap/MemoryThr and Rtabmap/TimeThr are unused. However, it seems like the sum of these time-consuming components (E.g. Occupancy Grid) are nowhere near the map_update time consumption. Is it expected for map_update time to escalate so rapidly? How does it get so high given the not-so-time-consuming subcomponents? In case some of these images are hard to view on your side, feel free to take a look at them here: Google Drive Folder I will post my rtabmap parameters used below. Thanks alot, Derek |
Re: Mysterious error regarding tf timeout
|
|
Here are my parameters. Thanks alot for looking through!
# # Parameters to be loaded into rtabmap.launch ################################### RTABMAP CORE MODULE ################################### rtabmap: # Sensor Input Parameters frame_id: base_link subscribe_depth: false subscribe_rgbd: true # Output Params queue_size: 30 # Increase if topics frequencies are different Mem/BinDataKept: true # Whether to store depth cloud from RGBD Camera, useful for debugging (Turn off to up FPS) # 3D Map vs 2D Map Grid/RayTracing: true # done for each occupied cell, filling unknown space between the sensor and occupied cells. Grid/NormalsSegmentation: false # Simple ground segmentation for 2D localization (NOTE: For outdoors, set NormalsSegmentation = True) Grid/MaxGroundHeight: 0.70 # (m) Everything below xx is Ground Grid/MaxObstacleHeight: 0 # (m) Everything below xx is Obstacle [0 to ignore] - (1.0m to remove ceiling in office) Grid/RangeMax: 75 # (m) Max Range of Laserscan to add to Map Grid/CellSize: 0.1 # (m) Resolution of Map Grid/PreVoxelFiltering: true # Whether to turn on voxel filter on input cloud (NOTE: Might be done on perception module) # Rate (Hz) at which new nodes are added to map Rtabmap/DetectionRate: 2 # RTAB-Map's parameters RGBD/NeighborLinkRefining: true # Correct odometry using the input lidar topic using ICP RGBD/ProximityBySpace: true # Find local loop closures based on the robot position in the map. RGBD/AngularUpdate: 0.01 # Map update Rate (Angular) RGBD/LinearUpdate: 0.01 # Map update Rate (Linear) RGBD/OptimizeFromGraphEnd: false # FALSE: on loop closures the graph will be optimized from the first pose in the map RGBD/ProximityPathMaxNeighbors: 10 # Use 10 if Reg/Strategy is using ICP Grid/FromDepth: false # FALSE: the occupancy grid is created from the laser scans (rather than RGBD Cam's pointcloud) Reg/Force3DoF: true # roll, pitch and z won't be estimated. Reg/Strategy: 1 # 0=Visual, 1=ICP, 2=Visual+ICP Mem/NotLinkedNodesKept: true # Keep not linked nodes in db (rehearsed nodes and deleted nodes). RGBD/SavedLocalizationIgnored: true # Don't always initialize at last location of previous session # Graph Optimizer (during loop closure) Optimizer/Strategy: 2 # 0=TORO, 1=g2o, 2=GTSAM and 3=Ceres Optimizer/Robust: false # If True, Robust graph optimization using Vertigo RGBD/OptimizeMaxError: 6 # Reject loop closures if optimization error ratio is greater than this value (0=disabled) # 0=SURF 1=SIFT 2=ORB 3=FAST/FREAK 4=FAST/BRIEF 5=GFTT/FREAK 6=GFTT/BRIEF 7=BRISK 8=GFTT/ORB 9=KAZE Kp/DetectorStrategy: 2 # KEYPOINT DETECTOR Vis/FeatureType: 2 # KEYPOINT DESCRIPTOR (Features) Kp/MaxFeatures: 500 # (Default: 500) Maximum features extracted from the images (0 means not bounded, <0 means no extraction) Vis/MinInliers: 15 # Minimum visual inliers to accept loop closure Kp/MaxDepth: 4.0 # Max depth for keypoints stored as vocabulary (m) Vis/MaxDepth: 4.0 # Max depth for features stored as vocabulary (m) Kp/MinDepth: 0.5 # Min depth for keypoints stored as vocabulary (m) Vis/MinDepth: 0.5 # Min depth for features stored as vocabulary (m) # ICP parameters Icp/VoxelSize: 0.5 # (DEFAULT: 0.0) How much to downsample pointcloud / laserscan Icp/MaxCorrespondenceDistance: 0.5 # (DEFAULT: 0.1) Max distance for point correspondences Icp/MaxTranslation: 0.5 # (DEFAULT: 0.2) Maximum ICP translation correction accepted (m) Icp/MaxRotation: 2 # (DEFAULT: 0.78) Maximum ICP rotation correction accepted (rad) Icp/Iterations: 10 # (DEFAULT: 30) Number of iterations ICP will attempt to converge to solution Icp/PM: true # (DEFAULT: true) Use libpointmatcher for ICP registration instead of PCL's implementation Icp/PMOutlierRatio: 0.6 # (DEFAULT: 0.95) TrimmedDistOutlierFilter/ratio Icp/PMMatcherKnn: 3 # (DEFAULT: 1) Number of nearest neighbors to consider it the reference Icp/PMMatcherEpsilon: 1 # (DEFAULT: 0.0) Approximation to use for the nearest-neighbor search Icp/CorrespondenceRatio: 0.1 # (DEFAULT: 0.1) Ratio of matching correspondences to accept the transform Icp/Epsilon: 0.00001 # (DEFAULT: 0.00001) Set the transformation epsilon (maximum allowable difference between two consecutive transformations) in order for an optimization to be considered as having converged to the final solution Icp/PointToPlaneK: 5 # (DEFALT: TRUE) Use point to plane ICP Icp/PointToPlaneRadius: 1.0 # (DEFAULT: 1.0) Search radius to compute normals for point to plane if the cloud doesn't have already normals |
|
Administrator
|
Hi,
Grid/RayTracing: true # done for each occupied cell, filling unknown space between the sensor and occupied cells. Grid/RangeMax: 75 # (m) Max Range of Laserscan to add to Map Grid/CellSize: 0.1 # (m) Resolution of Map Which kind of sensors are you using? a 75 meters local grid at 10 cm cell size in 3D with ray tracing, it will create very large local grids. When global map has to be updated (on graph optimization), it is likely to need large update times. In which kind of environment are you navigating? For indoor, you could decrease the Grid/RangeMax to 10 meters at most. cheers, Mathieu |
Re: Mysterious error regarding tf timeout
|
|
This post was updated on .
Hi Mathieu,
I am currently using an Intel NUC as an external PC connected to my robot. It runs all nodes, from perception, to rtabmap, to ROS navigation stack. There's plenty of processing power left after running all nodes. I am using the ouster OS1-32 lidar to build the 2d map (Compressing 3d pointcloud to 1 plane using in-built rtabmap libraries), a Realsense D435 camera for mapData scene reconstruction & to perform global loop closures, and odometry coming from the robot itself. I apologize, but I forgot to mention that i had an external launch parameter that sets Grid/3D to false as we are only generating 2d gridmaps for navigation via move_base. This parameters are tuned for outdoor navigation, so we had to increase Grid/RangeMax to 75 so that the robot can look much further to plan more efficient routes. When you mentioned Graph Optimizations, are you referring to the yellow ICP links? Any other insights for the long map update times? P.s. I changed the permissions of the google drive folder so that everyone can see the screenshots I have taken. Here is the link again: Google Drive Folder Thanks as always, Derek |
|
Administrator
|
Hi Derek,
Thanks for the details. So 75mx75m local grids at 10 cm cell size can have up to 562500 cells in 2D. If you have 100 nodes to update like this, it will require 100 x 562500 (56M) operations to update the global occupancy grid. Well, do you need to have access to full global occupancy grid at any time? You could use GridGlobal/MaxNodes parameter to limit the size of the assembled occupancy grid to nodes curently close to robot. To plan beyond that occupancy grid, you would have to use path planner embedded in rtabmap to plan to a node in the graph instead of a pose. While moving on the graph on previously visited areas, the occupancy grid will be incrementally updated. I tried this approach on a robot having to use an OctoMap while doing SLAM, as the OctoMap updates on loop closures are large, limiting the OctoMap to only nodes close to robot reduced that processing time, while keeping the robot able to do local planning in the OctoMap and using RTAB-Map graph global planning for longer paths. Other option is to increase GridGlobal/UpdateError (default 0.01m) so that global occupancy grid update happens less often, but will still increase in computation time like you've seen, just less often. A final option is to increase the cell size to 20 cm for example, thus it will cut by 4 the computation time when the global occuancy grid has to be updated. Make sure you subscribe to only one output map topic of rtabmap, so that only that map is generated. cheers, Mathieu PS: yes by graph optimzation, when yellow links are added there is an optimization. If the optimization correction goes over GridGlobal/UpdateError, the global map is re-assembled. |
Re: Mysterious error regarding tf timeout
|
|
This post was updated on .
Hi Mathieu,
That's a great point you have raised there; updating the map via 56M operations does seem to point to the long mapping update duration we have observed. Your recommended method of limited the size of the assembled occupancy grid seems like the most viable option for long-term SPLAM operations. I would like to clarify the difference between some of the memory management parameters. Please do correct me if I'm wrong. What is the difference between GridGlobal/MaxNodes and Rtabmap/MemoryThr? From my understanding, Rtabmap/MemoryThr moves some of the less important WM nodes (older and less weight) to LTM, in order to maintain a fix number of WM nodes for consistence mapping performance. These LTM nodes will no longer be considered for graph optimizations unless a loop closure is found (weight of LTM in the near vicinity will increase and be retrieved back to WM). Only nodes in WM will be used for the assembly of occupancy grid. On the other hand, GridGlobal/MaxNodes tells Rtabmap only to use a fix number of nodes close to the robot for the assembling of occupancy grid. This is basically the same as setting Rtabmap/MemoryThr, from the perspective of occupancy grid assembly, However, this parameter does not force rtabmap to move nodes to LTM, causing the number of WM nodes to grow unboundedly. Even if we were to maintain low map update durations, we may eventually come to a point where loop closure detection takes too long due to the large WM size. If my understanding is correct, setting Rtabmap/MemoryThr rather than GridGlobal/MaxNodes seems to be a more robust approach? I am currently rather hesitant to set Rtabmap/MemoryThr or Rtabmap/TimeThr. I have noticed that the global costmap sometimes becomes distorted whenever some nodes are moved from WM to LTM, similar to what someone else has pointed out. In fact, I suspect that one of my older problem is associated to this. I am not sure if you have any experience with the new global costmap generated by move_base not fitting the new 2d map generated by Rtabmap? Merry Christmas to you, Derek |
«
Return to Official RTAB-Map Forum
|
1 view|%1 views
| Free forum by Nabble | Edit this page |